
这几天,中国东谈主工智能初创公司DeepSeek火了,不仅在好意思区下载榜上卓绝了ChatGPT,还激励多个好意思国科技股的股价暴跌。好意思国总统特朗普称DeepSeek的出现“给好意思国联系产业敲响了警钟”。为何DeepSeek的出现会让好意思国如斯热心,致使有些弥留?谭主勾通中国工业互联网谈判院独家揭秘背后的原因↓↓↓
原因一:
高性价比冲击好意思国大模子独揽地位
DeepSeek可谓是用最少的钱,干最多的事。其推出的模子,在性能上和寰球现在顶尖的GPT-4o等大模子不相崎岖。但在老本上,OpenAI推行ChatGPT-4花消的老本高达7800万好意思元,还可能达到1亿好意思元。而DeepSeek大模子推行老本不到600万好意思元,仅为同性能模子的5%到10%。新模子推行顺次大幅度裁减了大模子行业的入局门槛,大限度预推行不再是科技巨头的专利。在模子推理层面,DeepSeek新推出的DeepSeek-R1,价钱为2.2好意思元/百万词元,而同性能OpenAI-o1的价钱为60好意思元/百万词元,DeepSeek概况是OpenAI的三十分之一。这种“低老本”记号着推理大模子调用插足平价时间,显耀改善了大模子的应用老本,对大模子在科研、企业等才略密集型产业中的应工具有紧要的价值。因此,不论是从基础谈判角度如故从生意层面上看,在推行和推理方面,对此前好意思国一些大模子公司的既有格局冲击比较大。
原因二:
格局更动,带来好意思国高新时期东谈主员着急
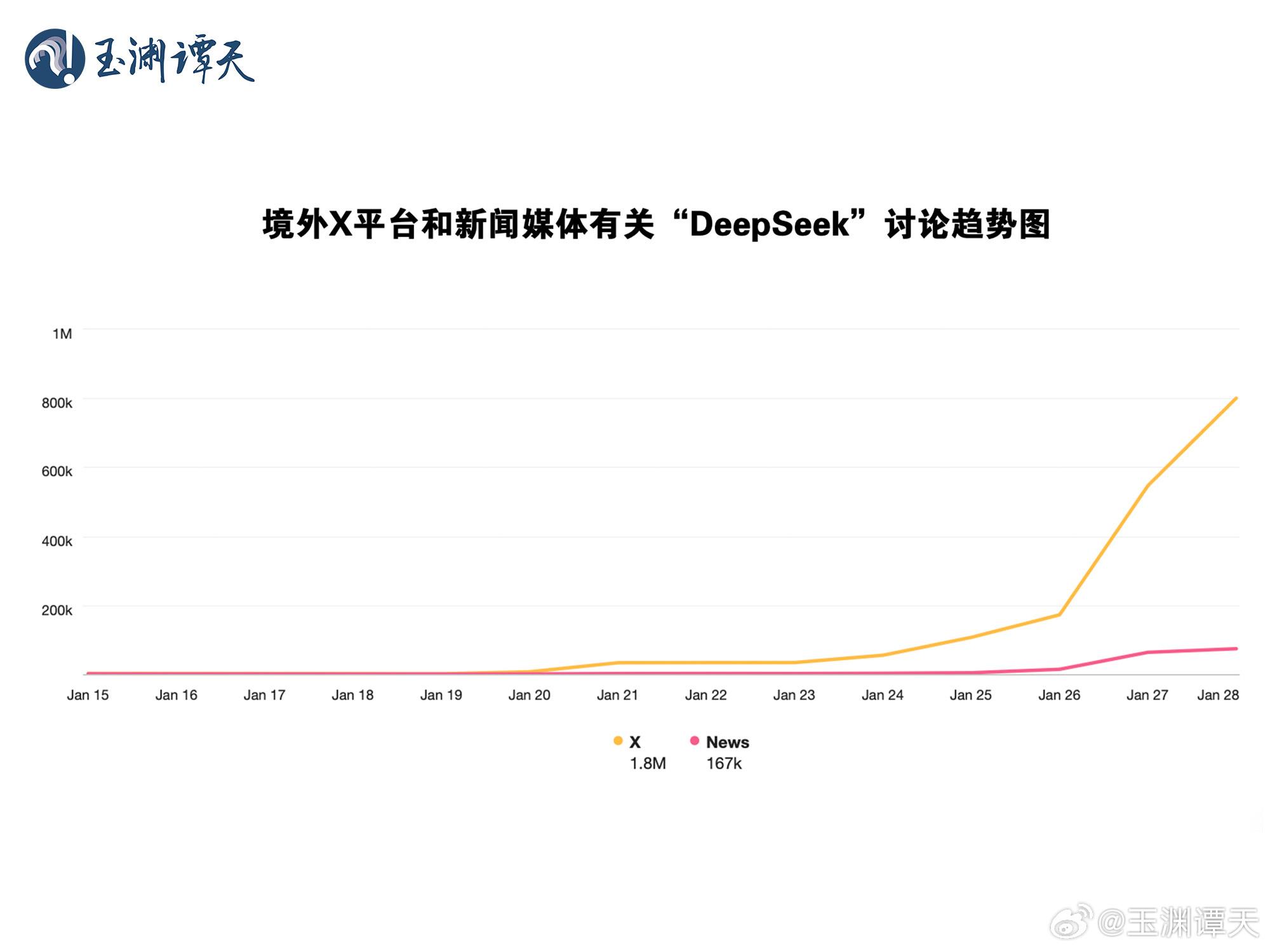
DeepSeek开发老本与好意思国大模子比拟大幅裁减,在于应用了不同的模子推行格局,陡立了好意思国堆砌算力的“英气”神气。在喂养学习数据这一大模子伏击门径上,OpenAI选拔了“东谈主海计策”,堆砌算卡、将资源围聚在算力,用海量数据投喂已矣技艺的普及。而DeepSeek比拟于“砸资源”选拔了另外一种神气。愚弄算法把数据进行归来和分类,流程选拔性措置之后再运送给大模子,最大优化算力已矣了老本的裁减和模子性能普及。现在看Meta花费了渊博资金推行Llama,可是效果上却莫得老本极低的DeepSeek效果好,Meta高层照旧在想考其职工是否在残害公司资金,而这也激励了不少企业时期东谈主员的着急,他们追思我方被质疑时期技艺和更动性从而失去使命。字据国际互联网平台对DeepSeek的谈判分析,外交媒体帖子的数目远高于新闻报谈,数目约是新闻报谈的十倍。时候上来看,外交媒体帖子的谈判早于新闻报谈,发酵着手比新闻媒体早了五天,这是由从事科技使命的自媒体东谈主以及职工圈层传播“破圈”酿成。
原因三:
国产大模子正在动须相应
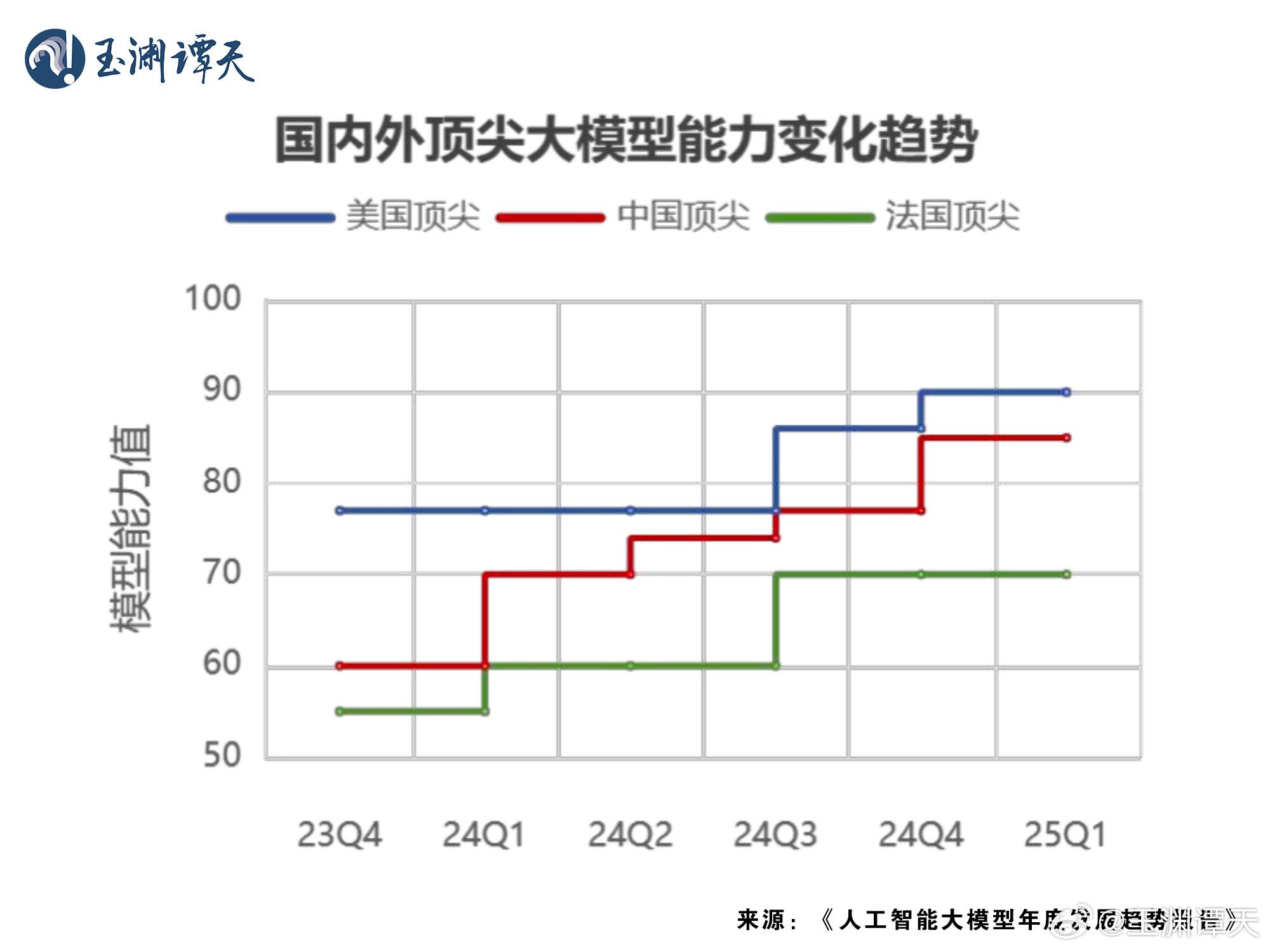
字据中国工业互联网谈判院推出的《东谈主工智能大模子年度发展趋势陈述》,与国际顶尖大模子技艺比拟,2024年国内大模子的技艺高出十分显耀。从2023年第四季度到2025年第一季度的测评表露,国表里大模子技艺差距减弱了快要75%。不错看出,DeepSeek的出现并不是所谓的“异军突起”,而是中国国内大模子合座发展的阶段性效力体现。此外,在陈述统计的寰球AI范围的投资上,中国55亿好意思元的投资额排在第二位,仅是第一位好意思国641亿投资额的不到十一分之一,中国明天在AI范围的发展上还有很大的空间。

如今,在DeepSeek对大师AI圈带来的升沉下,许多业内东谈主士皆喊出了“DeepSeek交班OpenAI”的标语。事实上,DeepSeek的出现,并不是要取代别东谈主,而是建议了更万般化的决策,陡立了国际主流大模子的阛阓独揽,在大模子的发展谈路上建议了不同于好意思西方的中国解法,让寰球看到了在大模子范围不是只好拼算力这一条路,再一次向寰球确认开云体育,什么是中国忠良。


